
Alex Fink think we already have enough information on the web: now it’s time to make sense of all of it. He’s built a fantastic tool called Otherweb that uses natural language processing to aggregate news from reputable outlets and filter out the junk. It even includes a search engine that can exclude any articles with affiliate links, hateful content, or lacking references. Oh and he’s built all of this without developing a business model.
Transcript
Ethan Zuckerman:
Hey everybody, welcome back to Reimagining the Internet. I am Ethan Zuckerman, your erstwhile host here in my office at the University of Massachusetts Amherst. And today we are talking with Alex Fink. Alex is the founder and CEO of the Otherweb, a new platform that allows readers to read news and commentary from around the web sorted by quality, free of clickbait. Alex is a serial entrepreneur. He’s the former VP of engineering for Orah, which built a live streaming VR camera. He’s more recently founder and CEO of Panopteo, which built a large number of computer vision products and he is now turning his expertise to the very thorny problems of quality news. Alex, welcome to the show.
Alex Fink:
Thank you so much for having me.
Ethan Zuckerman:
How did you end up deciding to focus on questions of news quality? You’re a guy who’s done a lot of work around image processing, some very tough technical problems. You’re now taking on a really incredibly difficult socio-technical problem. What got you interested in this field?
Alex Fink:
Right, so as you mentioned, I spent 15 years building perception systems, which essentially generate information. And at some point it has dawned on me that the world does not need more cameras or more information. We’re failing to make sense of what we have. And so I started trying to figure out what is this mechanism of sense making and why is it failing us. And it seems to me like the primary reason is that the majority of information we are generating is junk. It’s not real information, it just masquerades as information. I think the primary reason this is happening is that that’s the way the incentives are set up. Essentially from the late ’90s onward, we have been rewarding information or content in general that generates clicks and views because content is typically monetized through advertising and advertising typically pays the content creator per click or per view.
And so I think this is the root of all evil, what we are observing over the past 30 years. And I thought that the toolkit of trying to do computer vision analysis, let’s say, is fairly similar to the toolkit of natural language processing so why don’t I try to evaluate content quality and see if we can filter the junk out.
Ethan Zuckerman:
So this is a problem near and dear to my heart. I’ve written at some length about the dangers and the harms of advertising as a default model for the internet. Many people who are worried about advertising on the internet are worried about surveillance and what happens when we’re constantly being watched. There’s a wave of people since 2016 who are really worried about mis and disinformation and the idea that we are being misled by outside political actors. You seem focused almost in a different place. You seem focused on what we might think of as the Neil Postman problem, amusing ourselves to death. We are paying attention to stuff that is using all sorts of psychological tricks to demand our attention. Give us an example of what you see as junk information and where you’re finding it around the web at this point.
Alex Fink:
Well, I think it’s where do you avoid it around the web at this point. But sort of to go back to your characterization, I think we are all talking about the negative externalities, and I am viewing this more almost as a pure pollution problem. The way that we are monetizing content today is just generating a lot of garbage, a lot of pollution in the ecosystem. And yes, misinformation and disinformation are somewhat distinct in that their information to begin with. Somebody put out something that he thought or she thought was informative or disinformation on purpose, and that’s how you get those two.
But I think the primary problem is that occasionally I would open Google News and it would offer me an article from CNN titled Stop What You’re Doing and Watch this Elephant Play with Bubbles. And this is not information or disinformation or fake news, it’s just none of the above. It’s a pure time waster, but obviously it exists because people click on it. It seems like most things on the internet today exist just because people click on them. There is no other purpose.
So if you consider how many people today believe that the earth is flat, you would expect that in a world where there’s a Wikipedia article that explains the shape of the earth, that would not be the case. But somebody was incentivized to create content that promotes the idea that the earth is flat and some people clicked on it because it was promoted by Google or by Facebook or some other matchmaking service that essentially connects consumers of information to producers of information. There is incentive in creating that sort of nonsense, right? That probably falls more into the disinformation category, but I think that the incentives drive all of these ill effects.
Moreover, I think that because there is so much pure junk in the system, we are getting to the point where our senses are overwhelmed and we are just not using our faculties to actually filter out what we’re listening to. If you are in this constant mode of trying to filter out the elephants blowing bubbles, you’re trying to first not click on it. But even if you clicked on it accidentally, to read the first few sentences and see if this is going to be an elephant blowing bubbles or not. You might actually miss the elephant in the room, so to speak, and the real embedded disinformation or propaganda in there. It’s hard to be in what Kahneman would call system one and system two at the same time. So if you’re constantly in the system one of “Is this junk? Is this junk? Is this junk,” you’re going to not think critically about what you’re reading to the same extent that you otherwise would’ve.
Ethan Zuckerman:
So let’s talk about what the Otherweb actually is. You’ve launched a website and apps for Android and for Apple iOS. What happens when someone logs into the Otherweb?
Alex Fink:
So first they get a really brief onboarding that explains to them what they’re looking at and ask them a few basic questions. But after that, essentially they arrive at a platform that aggregates a lot of content, filters the obvious junk out and lets them do some basic customization for what their feed is going to look like.
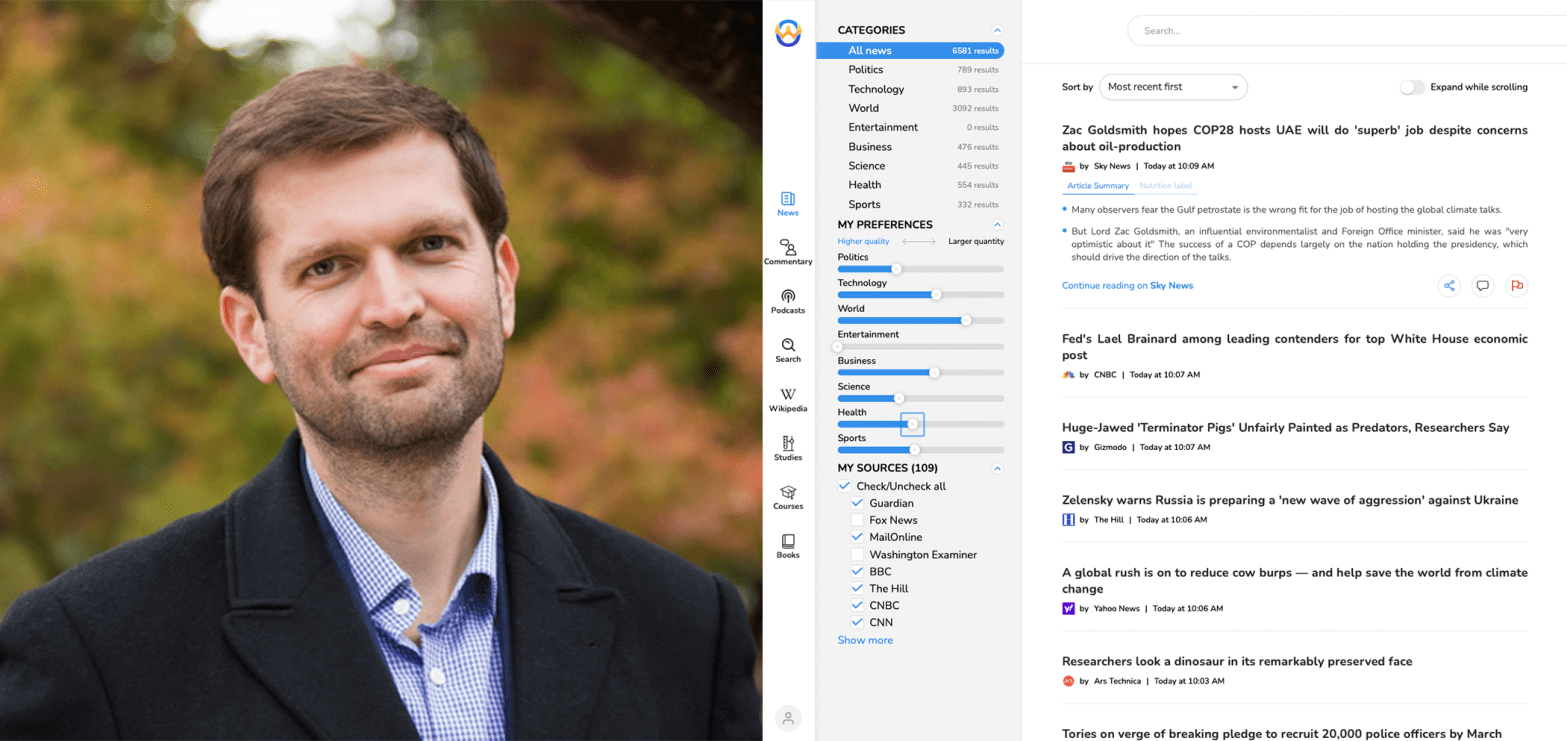
In the news domain, that is probably why most people use our app Right now, we are aggregating news articles from a little over a hundred outlets that we deem to be the best of the best. But then even from within those, we filter more than half of the articles out for just not being informative. We attach a nutrition label to all the articles that are left so you can take a look at that before you read the text of the article. We summarize the article into a few short bullet points so you can understand what it’s about and perhaps you don’t want to read the entire article after that if that is not a topic that you want to explore further. And we rewrite the headlines in case the original is clickbait because again, even within those good articles, sometimes you see headlines that just don’t match the content. They are phrased in a way that would maximize clicks instead of telling you what you’re actually about to read when you click on it.
Ethan Zuckerman:
And so just to dig down on a couple of pieces of that, I am a subscriber to the system, which I will say is for free. It was very easy to set up. Right now my sources include The Guardian, Reuters, MailOnline, but also Fox News, the Washington Examiner, BBC, Gizmodo, HuffPo. It’s quite a wide range and includes some things that I haven’t necessarily heard of, a number of European publications, some publications from Japan. It does give fairly straightforward headlines. I have a Guardian headline here, Saudi Arabia executes two more citizens for drug offenses as ex minister calls on UK to intervene. For me, perhaps what’s most impressive are these summaries. Now those are generated entirely by your system?
Alex Fink:
Yes, it’s essentially a summarizer model with some post-processing of the text to make it into need bullet points.
Ethan Zuckerman:
Is that something that you wrote? Did you adapt an existing system? How does that end up working?
Alex Fink:
It’s an existing transformer model with a bit of training on top for… Essentially we’ve generally trained it based on existing examples of how to summarize things like examples from AP, from other respectable journals that we found.
Ethan Zuckerman:
It’s impressive. It’s pretty great. It’s pulling these stories and fairly quickly turning them into five or six bullet points and it’s actually very easy to scan through a large amount of news very quickly. That raises a really interesting question. You are in some ways doing what Google News is doing, summarizing a lot of news, categorizing it together. I think maybe even more than Google News, I can imagine not having to click through very often. Are you worried that The Guardian or Reuters or everybody else who is sort of benefiting ultimately from clicks on the content are going to withdraw content from your system at some point?
Alex Fink:
We’re definitely worried about that, especially since copyright law is essentially one big gray area as it relates to aggregators. We’ve tried to be as careful and as open as we can. So if a website has paywalls, we avoid it because to us that just signals they don’t want to share their content. So even though we can scrape it, we don’t. We rewrite the headline, so we’re not using their original headline. We rewrite the bullet point summary itself so we’re not using any excerpt or any original text from the article. We do not include any images and we’ll link back to the source. So that’s about as much as we can do to stay within fair use guidelines. And yet, as you said, if one of those website reaches out to us and asks, “Please remove us,” we will.
What we have found is that there are many sources writing about the same thing. So the problem when you’re trying to aggregate news is not “Where do I find news?” It’s “How do I filter out the similar stories and the lower quality versions of the same story?” So even though, let’s say in financial news, there are a lot more paywalls, FT is paywall, Bloomberg is paywall, Forbes is paywall, et cetera, we still found CNBC and that’s enough to cover most stories, right? So with most of these, there are many alternatives. If some of them ask to be pulled out, we will gladly respect their request and just go with other sources for the same stories.
Ethan Zuckerman:
How are you dealing with that question of clustering similar stories? So for instance, I’m using the tool right now. I’ve told it only to show me politics stories and I’ve moved the slider all the way over so I’m just getting the largest number of politics stories possible. I’ve got 2,546 results. Is that going to give me duplicates of stories or is it trying to cluster things together?
Alex Fink:
We’re trying to cluster things together, but we’re being fairly conservative about it because sometimes stories are about the same topic, but they’re actually giving you a different point of view. And so we are currently only trying to cluster together things that are obvious duplicates or reprints or somebody essentially reprinting a Reuters’ story, let’s say, in their publication. But we are demanding at least 90% similarity between the headlines before grouping things together.
Ethan Zuckerman:
Got it. So you’re really looking for cases where someone is doing the same story instead of updating it or very clearly just doing a different version of the story, but not different content of one fashion or another.
Alex Fink:
Yeah. At this point we’re not grouping different stories on the same topic the way some other outlets do. I think probably the best one at doing that would be Ground News, which is another news aggregator that I personally like a lot even though they’re technically, I guess, competition, but they are doing the best job of grouping all the stories on a particular topic and dividing those by left, right, center so you know who’s writing about it.
Ethan Zuckerman:
Well, let’s talk about that a little bit. So first of all, you’ve already revealed that you are a user of news aggregators. What’s worked for you and what hasn’t worked for you with other aggregators out there?
Alex Fink:
So first of all, I read a lot of news. This is how I ended up, I guess, in this particular predicament. I’ve read RealClearPolitics. I’ve read allsides.com, I’ve viewed Google News for quite a long time. I find that each one of them has some strengths and some weaknesses. I guess we can start from Google News because it’s the biggest one. The biggest problem with Google News is junk. The stories that are relevant are relevant, but there is just a lot of things that aren’t, and there is no way to disable them. There’s no way to tell Google News to not show you the elephants blowing bubbles. It doesn’t matter how much I try. In fact, it doesn’t even just show it in the For you section. It shows it in the news. It shows it in a whole bunch of things where it shouldn’t appear.
The other problem is that they include a lot of paywall stories, and so almost 50% of the time you click on something, you end up in a paywall that ask you to pay. The reason I was reading an aggregator is so that I don’t have to go to all these different outlets where I have to pay. I guess Apple News did a better job trying to fix that particular problem. Google hasn’t. It could be that Google has to do this to not get sued by all these outlets for stealing their content.
Ethan Zuckerman:
Or it may actually be that Google News was linking to those outlets and those outlets have decided to paywall across the board, but also sort of recognizing that they want Google News to drive some revenue for them.
Alex Fink:
Right. But that to me makes Google News unusable even though I know a lot of people use it. And I used to use it until essentially until the first version of the Otherweb went into beta.
RealClearPolitics does a pretty decent job of aggregating opinion pieces from across the political aisle. I don’t think it has much in terms of actual breaking news or dispassionate commentary. Most of it is either far to the right or far to the left. I haven’t found that much middle.
Allsides.com does a great job, I think, of picking the same story from center, left, and the right, but they are covering a very small number of stories because of it, because I think it is so labor intensive for them to gather this content. So in many ways, we actually try to emulate allsides.com for a while and try to create this feature, but to automate it so that it’s not an editor picking the left, right, and center story, it’s a human. And what we found is that there’s probably no way to do that without angering a lot of people. And if you look at the Otherweb right now, we essentially don’t mention left, right or center at all. Political classification is just not included. Even though we have those models, we’ve open sourced them so people can use those models, but we don’t use them ourselves.
Ethan Zuckerman:
And beyond that, you’ve gone as far as sort of offering a challenge to anyone to sort of find political bias in your sort of core algorithms. What’s made you so confident about that and what’s made you want to make that a central feature of what you’re doing?
Alex Fink:
First of all, I should mention that the challenge about that is such that if somebody finds it, I will be grateful to them and I will gladly pay that amount for somebody to have found a bug in our system. It’s worth it. So I guess that in itself means I don’t really need to be as confident. It’s still worth it even if I’m wrong. But the thing is, we tried really hard to eliminate any bias from the training data sets from the actual way in which we trained it, from how we tested it, and so it shouldn’t be there. Now, is there a chance that it’s somehow managed to make it in? Of course. But we tried to balance data sets, balance annotators, balance everything. So to the best of my knowledge, there is nothing biased in them. But if I am proven wrong, then it will be worth it to pay the amount and to fix the bug.
Ethan Zuckerman:
Your core algorithm is trying essentially to create almost a nutritional information label for each of these stories. What are the aspects of that label? What are the different factors that you’re trying to detect for each of these stories that you’re putting within a newsfeed?
Alex Fink:
So what we try to do is take the idea of quality of a news story and try to figure out if there are smaller elements of that that we can define well in a way that most people would agree with. For example, is the headline attention grabbing or not? It’s a small element. It’s well defined. If I show the same headlines and the same stories to 10 people, there’s a pretty good chance that most of them will agree on the answer for that particular headline. And so we try to identify as many factors like this as we could.
In some cases, we relied on prior academic work. You can see the propaganda filter for example, that’s based on the QCRI dataset for propaganda. In some cases, we had to just make up our own because there was nothing well defined that we could find in the literature anywhere. But that is our attempt to break it down into smaller factors like subjectivity, like attention grabbing headlines, like formality of the language. Even though that is neither good nor bad, it’s a fact that we could tell people about the language being used. And to some extent we’re then trying to aggregate those together to come up with our definition of the quality of a news article. That part is not objectively defined. How we combine the smaller factors into one aggregate score is basically just us trying to match people’s intuition.
Ethan Zuckerman:
I’m really curious about the ambitions associated with the tool. So we’ve mostly talked so far about a news tab. There’s a commentary tab that works in a similar way. I assume that on commentary we’re going to have more of an obvious this is coming from the left, this is coming from the right. You also have tabs that are a little bit more peculiar. I want to talk first about the search one. You’ve basically created your own search engine here, or at least your own search filter, which allows you to block information that is not informative, that is hateful, that is offensive, highly subjective. What’s your thinking here?
Alex Fink:
Well, the thinking was that one of the ways people consume junk is they search on Google and then they get results and the majority of these results are actually junk. Specifically if you look at those filters, the one that’s most near and dear to my heart is the affiliate links filter because it seems to me like the best example of junk and search engines is when you search for reviews, all the results you get do not contain real reviews in them. For the most part, what you’re getting is link farms. That’s what you get when you search for reviews. That’s the same thing you get when you search for best laptop or best Mattress or best anything, you get link farms. And so I personally really wanted to create a way to filter that and to create a search engine that might not be as good as Google at aggregating all the information in the world, but it would be better at guaranteeing that what you get actually matches your query and doesn’t include a bunch of junk on top of it.
Ethan Zuckerman:
I assume that you’re using an existing search engine like Google or Bing, and then-
Alex Fink:
Not anymore.
Ethan Zuckerman:
Really?
Alex Fink:
We started from Bing, but the thing is you can’t really filter things out using NLP in real time on dozens of results. And so we essentially had to index a few tens of millions queries from Bing and then run all the filters offline so that we’re not doing them in real time. And now what you actually get when you run search on our website is our own search engine with our own index without calling external APIs. If you type in a really long tail query that we just don’t have any results for, then we’ll call Bing as a fallback.
Ethan Zuckerman:
Interesting, because I’m running a couple of queries against it and I’m sort of assuming that both you and I are actually pretty far down on the long tail. And we’re actually getting quite good results from it. Alex, this is not the 1990s. People don’t build new search engines these days. What’s the revenue model for all of this? You’re throwing an amazing amount of computational power at what sounds like solving a number of problems you’ve had with the information environment. I’m sure you’re operating on the intuition that other people may find these solutions helpful as well. Is this basically a way for you to have the tools for navigating the web that you wanted, or is this at some point a sustainable business?
Alex Fink:
My personal hypothesis is that probably the best way to monetize this without interfering with people’s use of it is to add advertising to the search results themselves. Because people who search typically have an intent to click on something relevant, and sometimes ads can be relevant. People who read news don’t really have the intent to click on something relevant to the news necessarily. And so advertising on the news would be annoying. Advertising on search I think would be acceptable as long as it’s actually relevant to what you’re searching. There are a few other ways this could potentially be monetized. One of them is our accidental creation of these things that you’re not supposed to create post ’90s, like our own search engine, which right now essentially we have an equivalent of being API that works almost as well for most keywords, right? Maybe there’s a way to monetize this as a B2B product in some sense. We have a few more things like this that are not really visible to the user of the product, but we’ve accidentally had to develop while creating this product.
Ethan Zuckerman:
So one thing that I find really fascinating about this, obviously the set of ideas that I’m obsessed with are what would the internet look like if we built it around a set of values rather than a set of revenue models? And it feels like in many ways that you’ve articulated a pretty straightforward set of values. You don’t like junk, you don’t like people wasting your attention. You have certain signals that are good triggers for “This person is going to waste my attention,” affiliate links more than six ads per page, certain types of language. And you’ve functionally rewired a good chunk of core internet services, news, search, to be more consistent with your values. My question is, why doesn’t the BBC provide this? Why doesn’t Deutsche Welle provide this? Is that a possible future for a product like this? This seems very consistent with organizations like public broadcasters whose job it is to try to provide high quality information environment for the people encountering their content.
Alex Fink:
It is. And I would say if you look at food as an analogy, first, you need to have a place that actually proves that people value quality in food, right? So first you need to create a sort of Whole Foods that has the organic, the local, maybe the pasture raised, some other ways to actually categorize foods to let people know what is quality and what isn’t. And then once that walled garden proves that the model works, that there’s demand for it, it starts going into the rest of the ecosystem and now suddenly Walmart is going to carry organic just because they also want to send that signal into the world, right?
So I think we’re following a similar approach where first we want to roll out this walled garden, “If you come here, you’ll never encounter junk.” That’s the one place where we’re guaranteeing this. Now we can go out to the rest of the world and say, “If you want some elements of what we have here, let us help. Let us give you some models that you can run. Maybe we can even create a data stream for ad network.” So ad networks can vary the price that they pay to content creators based on the quality of the underlying content. Maybe there are other ways in which this quality-based evaluation can propagate into the rest of the system. But first we have to show that somebody cares because if it turns out that we build it and nobody comes, then it’s pretty hard to go to the BBC and tell them you should do this.
Ethan Zuckerman:
So what’s your thinking on that so far? Are people willing to come? Are people excited about it?
Alex Fink:
It seems like some classes of people are. I would say that our target audience realistically is between 10 and 20% of the population. It’s probably not much higher than that. You can even do really simple shorthand math. Google has 2 billion users and academia.edu has 175 million. So you’re probably kept at roughly that kind of ratio.
Ethan Zuckerman:
Do you think that’s the group? Do you think it’s groups like academics? Who do you see as the likely users for the Otherweb?
Alex Fink:
It could be. So right now some elements maybe are embedded in the features of the product and some elements are just accidental because of who discovered it first. So I would say the most prolific users right now, for the most part, techies or academics, but more so techies just because those are the people that I had the easiest time reaching. The other two groups that I see represented if you try to categorize people on a different scale, are information junkies. People who really read a lot and people who have checked out of the news and this is the only way they’re willing to come back. And that second group is actually fairly large. I think the last stat I’ve seen is that 42% of adults in the US are trying to avoid the news just because it is so agitating and so unpleasant. And I think we can bring some percentage of them back.
Ethan Zuckerman:
I’m really curious to see that particular piece of it. I’m fascinated by this project. I think it’s phenomenally well thought out. I deeply admire the fact that you’re launching it without a revenue model and really asking the question of is this a worthwhile thing to have before figuring out who’s going to pay for that. I think it’s wonderful. And I think I agree with you that advertising driven by search is probably the least offensive sort of ad model out there. Chand Rajendra-Nicolucci and I wrote a paper on forgetful advertising that basically relies on advertising via search so that you can see the user’s intention and target based on that.
Alex Fink:
Almost every year of the past decade, there has been some event that makes this the right time to launch something like this. It seems like we just keep going from one calamity to the other, and every time we think it cannot possibly get worse than this, and then the next year it gets even worse. And so I think from now on, it’s always going to be the right time to launch something like this just because this is the biggest problem facing us. We are just drowning in junk. And I truly believe that our brains are potentially a good ML machine, but it’s garbage and garbage out. If most of what we consume as junk, our actions will become junk. And so it’s time to find some sort of solution to it.
Ethan Zuckerman:
Well, Alex Fink, you’ve offered really two fascinating things today. One is a diagnosis that’s frankly quite different from most diagnoses we’ve heard of this show, that we shouldn’t be worried as much about partisanship or about mis and disinformation as we should. Simply about junk and people wasting our attention. You’re putting forward one of the most ambitious responses to it I’ve ever seen anyone put forward. Essentially, not only an alternative to Google News, but frankly an alternative to Google with a podcast player thrown into it. It’s available at otherweb.com. It is free to use. It has at this point no business model, but perhaps if other people start using it, a business model will emerge from it. Alex, such a pleasure having you here.
Alex Fink:
Likewise. Thank you so much for having me.